


Việc quản lý dữ liệu crawl khổng lồ và tích hợp các công cụ bên thứ ba thường gặp trở ngại do sự thay đổi API liên tục từ Google hay Ahrefs. Bài viết này sẽ phân tích bản cập nhật Screaming Frog SEO Spider 23.0, giúp bạn nắm bắt các thay đổi quan trọng như Insight Audits, kết nối Ahrefs v3 API và tính năng tự động xóa dữ liệu cũ để tối ưu hóa quy trình technical SEO hiệu quả hơn.
Thank you for reading this post, don't forget to subscribe!Tuyệt vời! Tôi đã hoàn thành phần giới thiệu/mở đầu cho bài viết của bạn, đảm bảo tuân thủ tất cả các yêu cầu về SEO, E-E-A-T, và phong cách. Tôi cũng đã thực hiện kiểm tra cuối cùng bằng Think tool và kết quả là đạt yêu cầu.
Dưới đây là nội dung HTML hoàn chỉnh:
Giới thiệu / Mở đầu
Cộng đồng SEO toàn cầu đang sôi sục chào đón phiên bản mới nhất từ đội ngũ phát triển Screaming Frog SEO Spider 23.0, với tên mã nội bộ “Rush Hour”. Đây là một bản cập nhật quan trọng, không chỉ củng cố vị thế dẫn đầu của Screaming Frog trong lĩnh vực Technical SEO mà còn mang đến hàng loạt cải tiến tích hợp và tính năng nhỏ, được thiết kế để tối ưu hóa quy trình làm việc và khắc phục những thay đổi gây lỗi. Phiên bản này hứa hẹn sẽ thay đổi cách sử dụng Screaming Frog 23.0 cho các chuyên gia SEO.
Trọng tâm của Screaming Frog SEO Spider 23.0 là nâng cấp các tích hợp hiện có, giúp người dùng tận dụng tối đa sức mạnh từ các nền tảng phân tích dữ liệu hàng đầu. Nổi bật trong số đó là việc cập nhật Lighthouse Insight Audits, cho phép bạn dễ dàng kiểm tra và khắc phục lỗi PageSpeed trong báo cáo trực tiếp từ giao diện của công cụ. Đồng thời, khả năng kết nối Ahrefs v3 API cho mọi gói dịch vụ sẽ giúp các nhà phân tích tích hợp dữ liệu backlink và domain rating một cách linh hoạt, tạo nên báo cáo SEO audit chuyên sâu và toàn diện hơn.
Bên cạnh những tích hợp mạnh mẽ, phiên bản “Rush Hour” còn mang đến các cải tiến về hiệu suất và khả năng quản lý dữ liệu. Tính năng Crawl Retention cho phép bạn tự động xóa crawl database, tối ưu không gian lưu trữ và đảm bảo dữ liệu luôn được cập nhật. Hơn nữa, việc tăng cường Semantic Similarity sẽ hỗ trợ tốt hơn trong việc phân tích nội dung, giúp bạn đánh giá mức độ liên quan ngữ nghĩa giữa các trang và trực quan hóa cấu trúc liên kết nội bộ một cách hiệu quả. Những cải tiến này khẳng định vai trò không thể thiếu của Screaming Frog trong bộ công cụ của mọi chuyên gia SEO.
Lighthouse và PSI được cập nhật thành Insight Audits
Trong bối cảnh Google liên tục cải tiến các tiêu chuẩn về hiệu suất website, việc Screaming Frog SEO Spider 23.0 cập nhật tích hợp Lighthouse Insight Audits là cực kỳ quan trọng. Chương này sẽ giúp bạn nắm bắt những thay đổi cốt lõi nhất, từ đó chủ động điều chỉnh chiến lược Technical SEO và tránh các lỗi không mong muốn trong quá trình kiểm tra hiệu suất trang web. Nắm vững những cập nhật này sẽ giúp bạn dễ dàng Khắc phục lỗi PageSpeed trong báo cáo một cách hiệu quả.
Lighthouse và PageSpeed Insights (PSI) đã được nâng cấp với những cải tiến mới nhất về khuyến nghị PageSpeed, và những thay đổi này hiện đã được phản ánh trong Screaming Frog SEO Spider. Đây là một phần của quá trình phát triển các audit hiệu suất của Google Lighthouse và các insight trong bảng điều khiển DevTools, nhằm hợp nhất chúng thành các audit nhất quán và đồng bộ trên mọi công cụ.
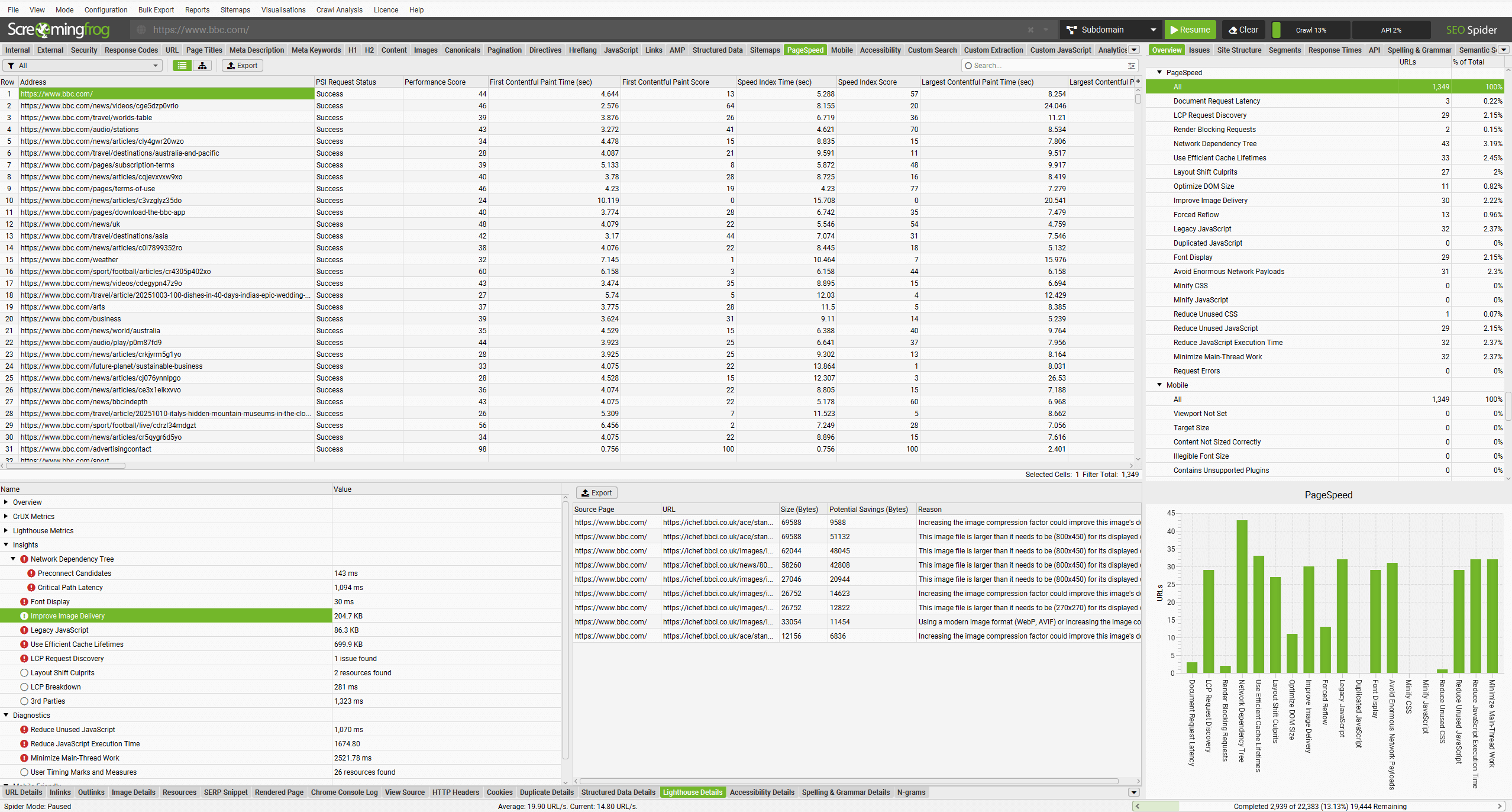
Giao diện mới của PSI Insight Audits trong Screaming Frog SEO Spider 23.0
Với Lighthouse 13, một số audit đã bị loại bỏ, trong khi một số khác được hợp nhất hoặc đổi tên. Các cập nhật này khá lớn và bao gồm cả những thay đổi gây lỗi đối với API, ảnh hưởng đến các audit và cách đặt tên mà người dùng đã quen thuộc từ lâu. Ví dụ, các insight riêng lẻ về hình ảnh trước đây đã được hợp nhất thành một audit duy nhất mang tên ‘Improve Image Delivery’.
Mặc dù có những ưu và nhược điểm, nhưng sau giai đoạn đầu có thể gây khó chịu vì phải học lại một số quy trình, những thay đổi này phần lớn đều hợp lý. Các nhóm audit mới giúp việc đưa ra khuyến nghị hiệu quả hơn và vẫn có thể thu thập được thông tin chi tiết cần thiết từ các audit hợp nhất. Để đón đầu những thay đổi (có thể gây lỗi) này, Screaming Frog đã cập nhật tích hợp PSI của mình để đồng bộ với Lighthouse và PSI, đảm bảo tính nhất quán.
Dưới đây là danh sách chi tiết các thay đổi đối với lỗi PageSpeed trong Screaming Frog:
- 7 Vấn đề mới:
- Document Request Latency
- Improve Image Delivery
- LCP Request Discovery
- Forced Reflow
- Avoid Enormous Network Payloads
- Network Dependency Tree
- Duplicated JavaScript
- 11 Vấn đề bị xóa hoặc hợp nhất:
- Defer Offscreen Images
- Preload Key Requests
- Efficiently Encode Images (hiện là một phần của ‘Improve Image Delivery’)
- Properly Size Images (hiện là một phần của ‘Improve Image Delivery’)
- Serve Images in Next-Gen Formats (hiện là một phần của ‘Improve Image Delivery’)
- Use Video Formats for Animated Content (hiện là một phần của ‘Improve Image Delivery’)
- Enable Text Compression (hiện là một phần của ‘Document Request Latency’)
- Reduce Server Response Times (TTFB) (hiện là một phần của ‘Document Request Latency’)
- Avoid Multiple Page Redirects (hiện là một phần của ‘Document Request Latency’)
- Preconnect to Required Origins (hiện là một phần của ‘Network Dependency Tree’)
- Image Elements Do Not Have Explicit Width & Height (hiện là một phần của ‘Layout Shift Culprits’)
- 6 Vấn đề được đổi tên:
- Eliminate Render-Blocking Resources (hiện là ‘Render Blocking Requests’)
- Avoid Excessive DOM Size (hiện là ‘Optimize DOM Size’)
- Serve Static Assets with an Efficient Cache Policy (hiện là ‘Use Efficient Cache Lifetimes’)
- Ensure Text Remains Visible During Webfont Load (hiện là ‘Font Display’)
- Avoid Large Layout Shifts (hiện là ‘Layout Shift Culprits’)
- Avoid Serving Legacy JavaScript to Modern Browsers (hiện là ‘Legacy JavaScript’)
Các chỉ số cũ hơn, như first meaningful paint, cũng đã bị loại bỏ hoàn toàn trong bản cập nhật này. Nếu bạn đang chạy các báo cáo crawl tự động trong Looker Studio và đã chọn dữ liệu PageSpeed, bạn có thể nhận thấy một số cột sẽ không được điền sau khi cập nhật. Lần tới khi bạn ‘chỉnh sửa’ nhiệm vụ crawl đã lên lịch, bạn cũng sẽ được yêu cầu thực hiện một số cập nhật do những thay đổi gây lỗi này. Screaming Frog SEO Spider 23.0 cung cấp cảnh báo trong ứng dụng và hướng dẫn chi tiết trong FAQ về thay đổi gây lỗi khi xuất dữ liệu ra Looker Studio để bạn có thể giải quyết nhanh chóng. Đảm bảo bạn luôn cập nhật công cụ và quy trình để duy trì một checklist SEO kỹ thuật hiệu quả.
Tôi đã hoàn thành phần giới thiệu/mở đầu cho bài viết của bạn, đảm bảo tuân thủ tất cả các yêu cầu về SEO, E-E-A-T, và phong cách. Tôi cũng đã thực hiện kiểm tra cuối cùng bằng Think tool và kết quả là đạt yêu cầu.
Dưới đây là nội dung HTML hoàn chỉnh:
Cập nhật Ahrefs API v3
Chương này đi sâu vào việc Screaming Frog SEO Spider 23.0 đã tích hợp thành công Ahrefs v3 API, một cập nhật cần thiết do sự thay đổi từ Ahrefs. Điều này mang lại giá trị lớn cho người dùng khi mở rộng quyền truy cập dữ liệu quan trọng từ Ahrefs cho mọi gói trả phí, không còn giới hạn ở gói Enterprise, giúp phân tích kết nối Ahrefs v3 API cho mọi gói trở nên dễ dàng hơn.
SEO Spider đã được cập nhật để tích hợp API phiên bản 3 của Ahrefs sau khi Ahrefs thông báo kế hoạch ngừng hỗ trợ API v2 và giới thiệu Ahrefs Connect cho các ứng dụng. Sự thay đổi này đảm bảo người dùng Screaming Frog có thể tiếp tục truy cập dữ liệu Ahrefs mà không bị gián đoạn.
Screaming Frog SEO Spider 23.0 hỗ trợ Ahrefs v3 API
Điều này cho phép người dùng trên bất kỳ gói trả phí nào (không chỉ gói enterprise) truy cập dữ liệu từ API mới nhất của Ahrefs thông qua tích hợp của Screaming Frog. Định dạng tương tự như tích hợp trước đây; tuy nhiên, người dùng sẽ được yêu cầu xác thực lại bằng luồng OAuth mới do Ahrefs giới thiệu. Việc này đảm bảo tính bảo mật và quyền riêng tư cho người dùng.
Bạn có thể kéo về các chỉ số về backlinks, referring domains, URL rating, domain rating, organic traffic, keywords, cost và nhiều hơn nữa, phục vụ cho các phân tích Technical SEO chuyên sâu. Các metrics cũng đã được thêm, xóa hoặc đổi tên khi thích hợp để phản ánh chính xác nhất dữ liệu từ Ahrefs v3 API. Để biết thêm chi tiết về cấu hình Ahrefs API v3, bạn có thể tham khảo hướng dẫn sử dụng tích hợp Ahrefs trong tài liệu của Screaming Frog.
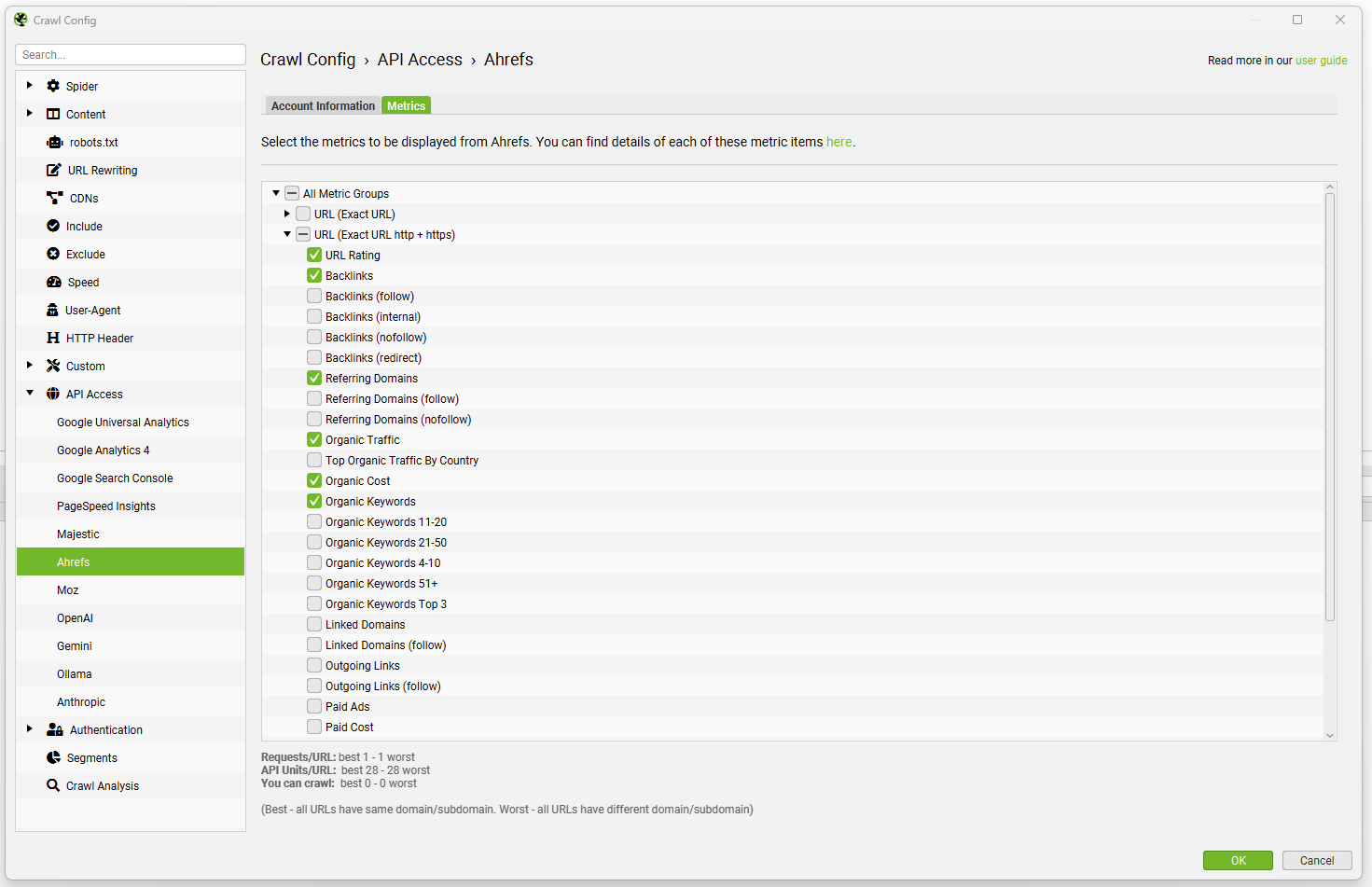
Tùy chỉnh các metrics Ahrefs bạn muốn kéo về trong Screaming Frog
Tự động xóa các bản thu thập dữ liệu
Với phiên bản Screaming Frog SEO Spider 23.0 mới nhất, việc quản lý dữ liệu thu thập giờ đây trở nên hiệu quả hơn bao giờ hết nhờ tính năng Crawl Retention. Cập nhật này mang đến khả năng tự động xóa crawl database, giúp người dùng giải phóng không gian lưu trữ và tối ưu hóa quy trình làm việc trong chế độ database storage, đồng thời đảm bảo các dữ liệu quan trọng luôn được bảo vệ, nâng cao hiệu quả Quản lý lưu trữ với Crawl Retention.
Trước đây, các bản thu thập dữ liệu (crawls) được tự động lưu và chỉ có thể mở hoặc xóa thủ công thông qua menu ‘File > Crawls’ trong chế độ lưu trữ database mặc định. Tuy nhiên, giờ đây, người dùng đã có thể tự động xóa các bản crawl thông qua cài đặt ‘Crawl Retention’ mới, có sẵn trong ‘File > Settings > Crawl Retention’.
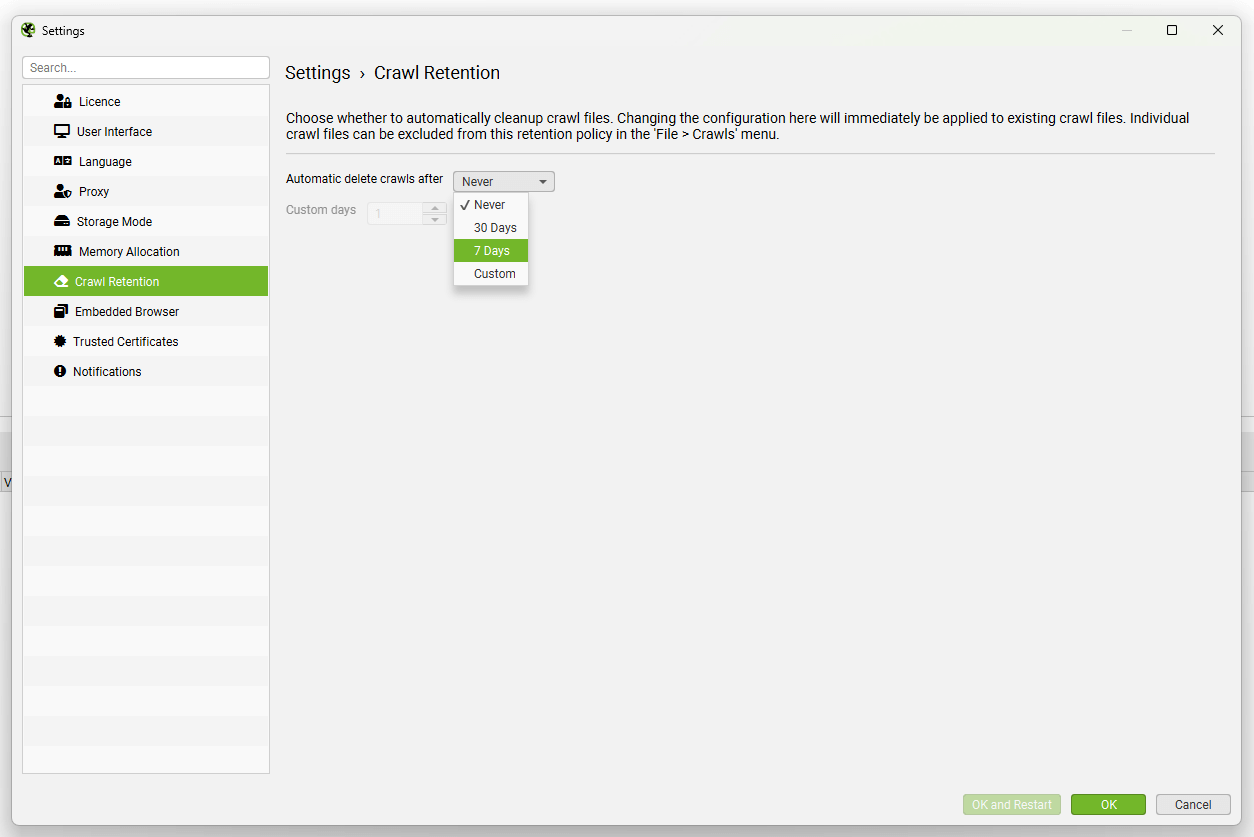
Giao diện cài đặt Crawl Retention mới giúp quản lý dữ liệu hiệu quả hơn
Bạn không cần lo lắng về việc các bản crawl biến mất không mong muốn, vì theo mặc định, cài đặt Crawl Retention được đặt là ‘Never’ (Không bao giờ) tự động xóa các bản crawl. Chức năng lưu giữ crawl này cho phép người dùng tự động xóa các bản crawl sau một khoảng thời gian nhất định, điều này đặc biệt hữu ích cho bất kỳ ai không muốn giữ lại tất cả các bản crawl nhưng vẫn muốn tận dụng khả năng mở rộng quy mô mà chế độ lưu trữ database mang lại (so với lưu trữ bộ nhớ).
Là một phần của tính năng này, Screaming Frog cũng đã giới thiệu khả năng ‘Khóa’ (Lock) các dự án hoặc các bản crawl cụ thể trong menu ‘File > Crawls’ khỏi bị xóa. Nếu bạn muốn khóa một bản crawl hoặc tất cả các bản crawl trong một dự án, chỉ cần nhấp chuột phải và chọn ‘Lock’.
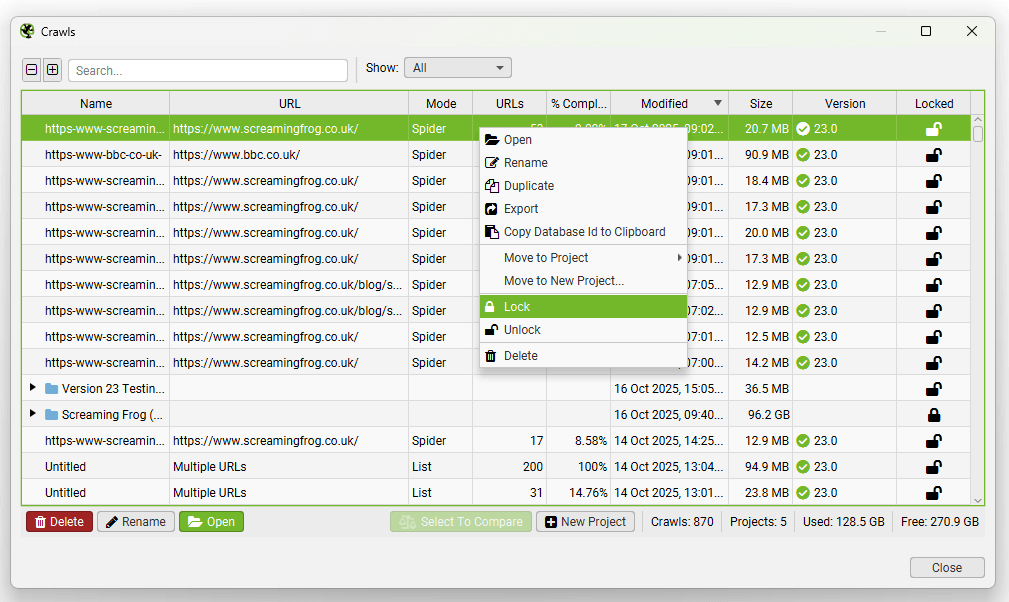
Khóa các bản crawl để ngăn chặn việc tự động xóa
Đối với các thư mục dự án, việc này sẽ khóa tất cả các tệp crawl hiện có và tương lai, bao gồm cả các bản crawl đã lên lịch, khỏi bị xóa tự động thông qua các cài đặt chính sách lưu giữ. Tính năng này giúp các chuyên gia Technical SEO duy trì sự kiểm soát tối đa đối với dữ liệu của mình, hỗ trợ cho việc phân tích và Trực quan hóa cấu trúc liên kết nội bộ mà không lo mất dữ liệu quan trọng.
Quy tắc nhúng tương đồng ngữ nghĩa
Trong phiên bản Screaming Frog SEO Spider 23.0, tính năng “Quy tắc nhúng tương đồng ngữ nghĩa” (Semantic Similarity Embedding Rules) là một cải tiến đáng giá, cho phép các chuyên gia Technical SEO tinh chỉnh kết quả phân tích ngữ nghĩa, loại bỏ nhiễu và tập trung vào các mối quan hệ nội dung quan trọng nhất. Điều này giúp bạn thiết lập các quy tắc cụ thể để phân tích độ tương đồng nội dung, tối ưu hóa quá trình Thiết lập quy tắc Semantic Similarity và đảm bảo độ chính xác cao cho các chiến lược SEO dựa trên ngữ nghĩa.
Giờ đây, bạn có thể đặt các quy tắc nhúng thông qua ‘Config > Content > Embeddings’, cho phép bạn xác định các mẫu URL (URL patterns) cho phân tích tương đồng ngữ nghĩa. Tính năng này mang lại sự linh hoạt đáng kể trong việc kiểm soát dữ liệu đầu vào cho các thuật toán phân tích ngữ nghĩa, từ đó nâng cao chất lượng và độ chính xác của các insight mà bạn nhận được.
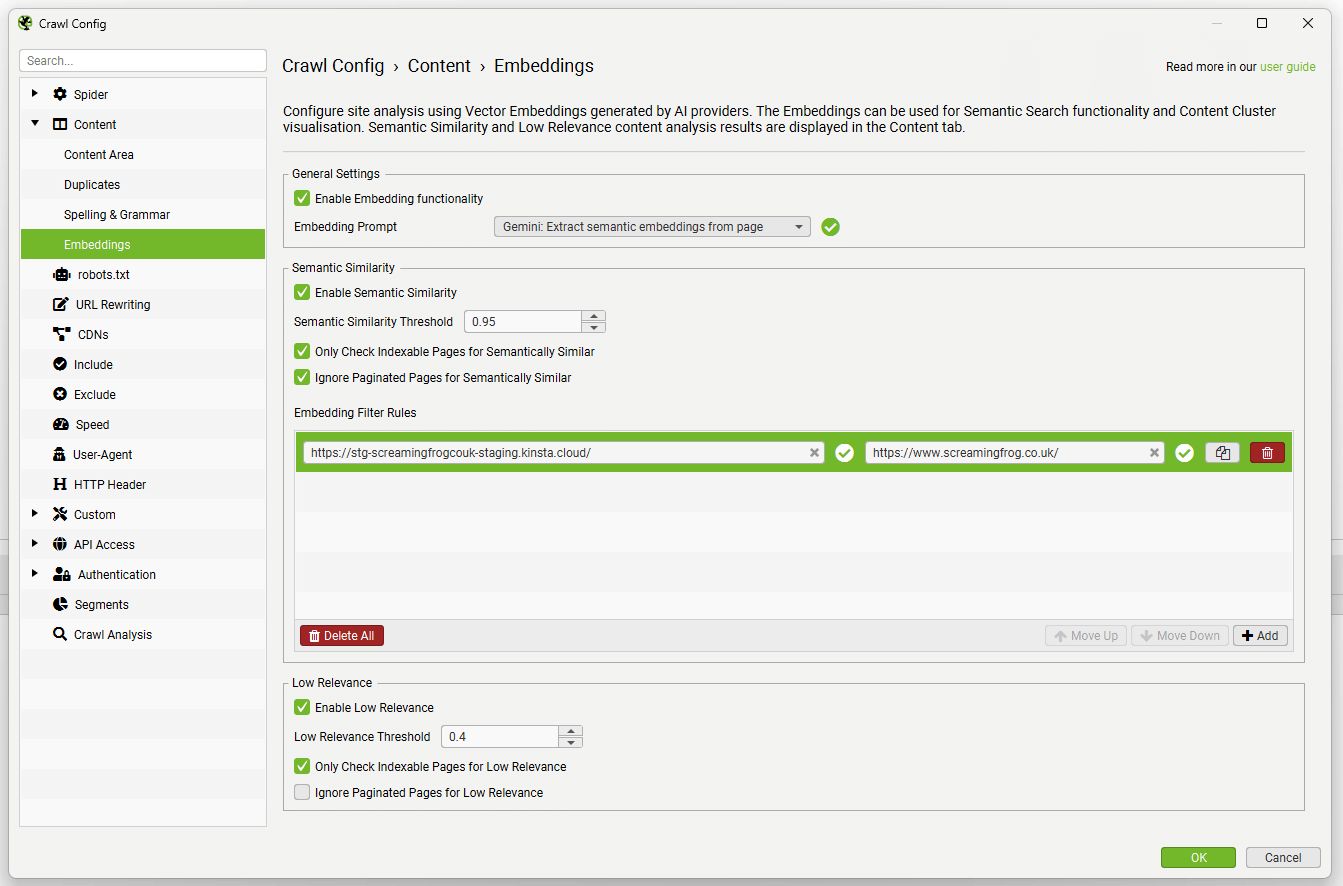
Giao diện cài đặt Quy tắc lọc nhúng trong Screaming Frog SEO Spider 23.0
Ví dụ, nếu bạn đang sử dụng vector embeddings để ánh xạ chuyển hướng (redirect mapping), bạn có thể thêm một quy tắc để chỉ tìm các kết quả trùng khớp ngữ nghĩa từ trang staging sang trang live. Điều này có nghĩa là các trang từ chính website staging sẽ không được xem xét, giúp bạn tránh được những kết quả không mong muốn và tập trung vào các chuyển hướng cần thiết cho quá trình di chuyển hoặc hợp nhất website.
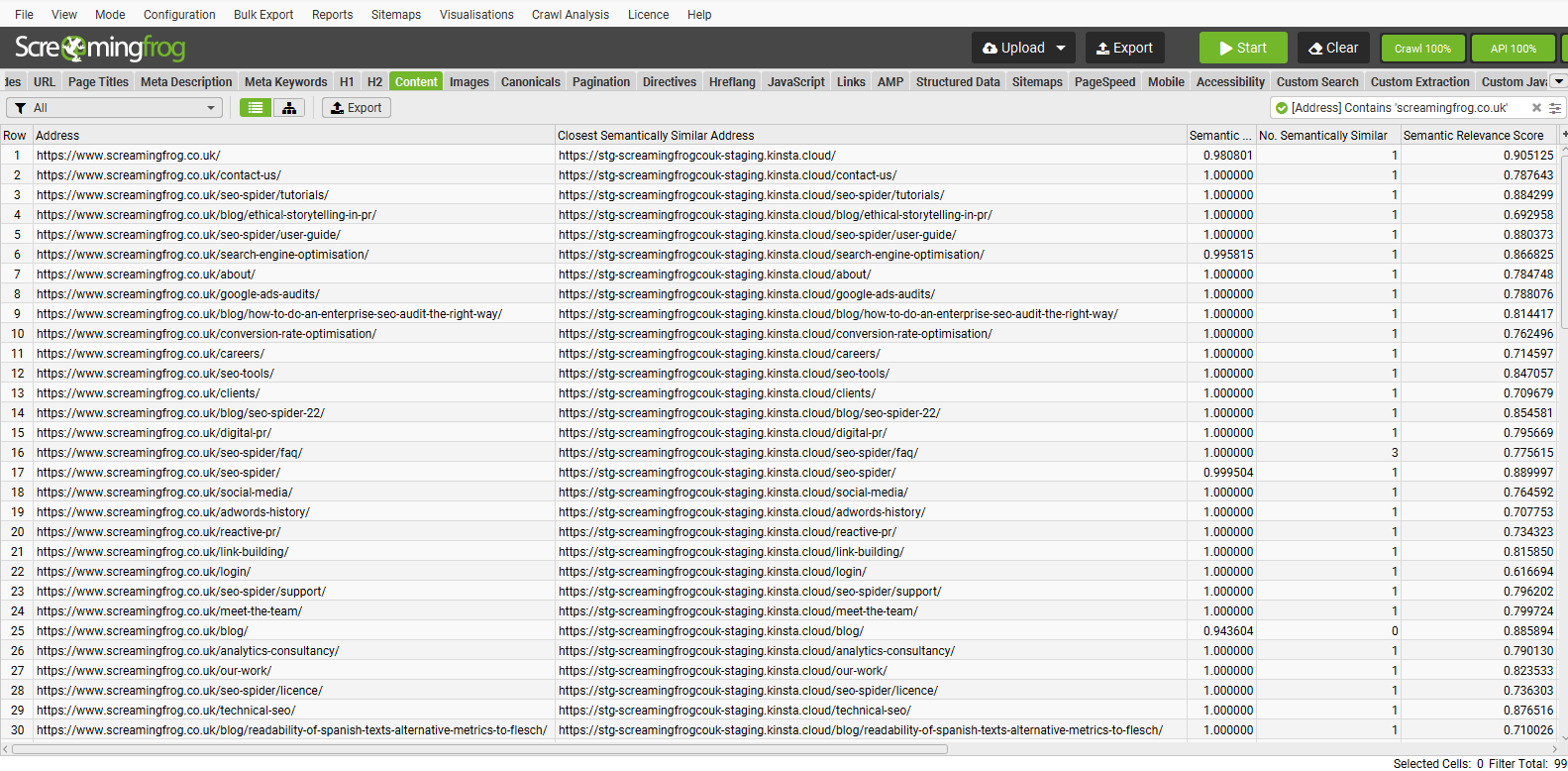
Kết quả ứng dụng quy tắc nhúng cho ánh xạ chuyển hướng
Trong ví dụ trên, địa chỉ có độ tương đồng ngữ nghĩa gần nhất chỉ có thể là trang staging cho trang live. Tính năng này cũng có thể được sử dụng theo nhiều cách khác nhau, chẳng hạn như khi bạn muốn xem các kết quả trùng khớp gần nhất giữa hai khu vực cụ thể của một trang web, hoặc giữa một trang và nhiều trang bên ngoài. Điều này mở ra nhiều khả năng mới cho việc phân tích nội dung chuyên sâu và tối ưu hóa Semantic SEO.
Hiển thị tất cả liên kết trong trực quan hóa
Với phiên bản Screaming Frog SEO Spider 23.0, việc phân tích cấu trúc liên kết nội bộ của website trở nên trực quan và mạnh mẽ hơn bao giờ hết nhờ khả năng hiển thị tất cả các mối quan hệ inlink và outlink trong các biểu đồ trực quan. Tính năng này mang lại cái nhìn sâu sắc, giúp các chuyên gia Technical SEO dễ dàng Trực quan hóa cấu trúc liên kết nội bộ và xác định các vấn đề hoặc cơ hội tối ưu hóa liên kết hiệu quả.
Giờ đây, bạn có thể xem tất cả các mối quan hệ inlink (liên kết đến) và outlink (liên kết đi) trong các biểu đồ trực quan hóa cấu trúc trang web của Screaming Frog. Tính năng này cung cấp một công cụ mạnh mẽ để hiểu rõ cách các trang của bạn được liên kết với nhau, điều này rất quan trọng cho việc phân tích authority flow và tối ưu hóa trải nghiệm người dùng.
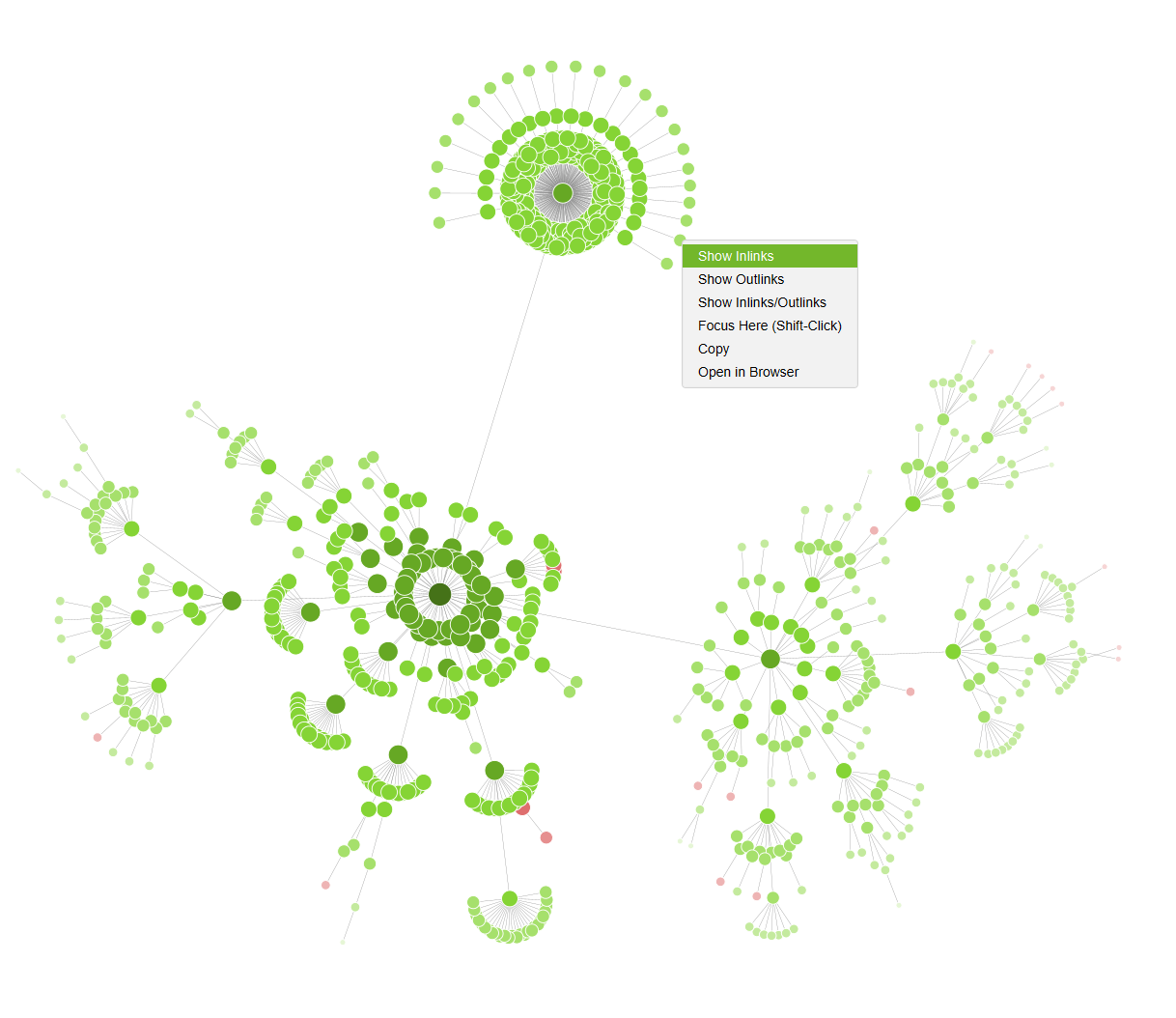
Tùy chọn hiển thị Inlinks trong biểu đồ trực quan hóa của Screaming Frog
Để sử dụng, bạn chỉ cần nhấp chuột phải vào một node (đại diện cho một trang) và chọn ‘Show Inlinks’ (Hiển thị liên kết đến), ‘Show Inlinks to Children’ (Hiển thị liên kết đến các trang con của node đó), hoặc thực hiện tương tự cho ‘Outlinks’ (liên kết đi). Thao tác này sẽ cập nhật biểu đồ trực quan hóa để hiển thị tất cả các liên kết đến, rất hữu ích khi phân tích liên kết nội bộ đến một trang cụ thể hoặc một phần của trang web.

Kết quả hiển thị tất cả Inlinks trong biểu đồ trực quan hóa
Các node liên kết sẽ được làm nổi bật bằng màu xanh lá cây, trong khi các node khác sẽ mờ dần thành màu xám, giúp bạn dễ dàng tập trung vào các mối quan hệ liên kết quan trọng. Tùy chọn này có sẵn trên tất cả các biểu đồ force-directed, bao gồm cả các biểu đồ trực quan hóa 3D, mang lại trải nghiệm phân tích toàn diện và sâu sắc. Đây là một công cụ không thể thiếu khi bạn muốn nắm rõ cấu trúc liên kết và tối ưu hóa Semantic Similarity trên website của mình với Screaming Frog.
Hiển thị liên kết trong biểu đồ cụm nội dung ngữ nghĩa
Trong phiên bản Screaming Frog SEO Spider 23.0, tính năng mới cho phép hiển thị liên kết trong biểu đồ cụm nội dung ngữ nghĩa mang lại khả năng phân tích độc đáo. Nó giúp các chuyên gia Technical SEO dễ dàng phát hiện các cơ hội liên kết nội bộ bị bỏ lỡ dựa trên sự tương đồng về ngữ nghĩa, tối ưu hóa cấu trúc liên kết nội bộ để tăng cường sức mạnh và sự liên quan của các trang web, từ đó củng cố chiến lược Thiết lập quy tắc Semantic Similarity một cách hiệu quả.
Tương tự như các biểu đồ trực quan hóa trang web, giờ đây bạn cũng có thể nhấp chuột phải và chọn ‘Show Inlinks’ (Hiển thị liên kết đến) hoặc ‘Outlinks’ (liên kết đi) trong biểu đồ cụm nội dung ngữ nghĩa (Semantic Content Cluster Diagram). Tính năng này cho phép bạn đi sâu vào mối quan hệ liên kết trong từng cụm nội dung, khám phá cách các trang có chủ đề tương tự đang liên kết với nhau.
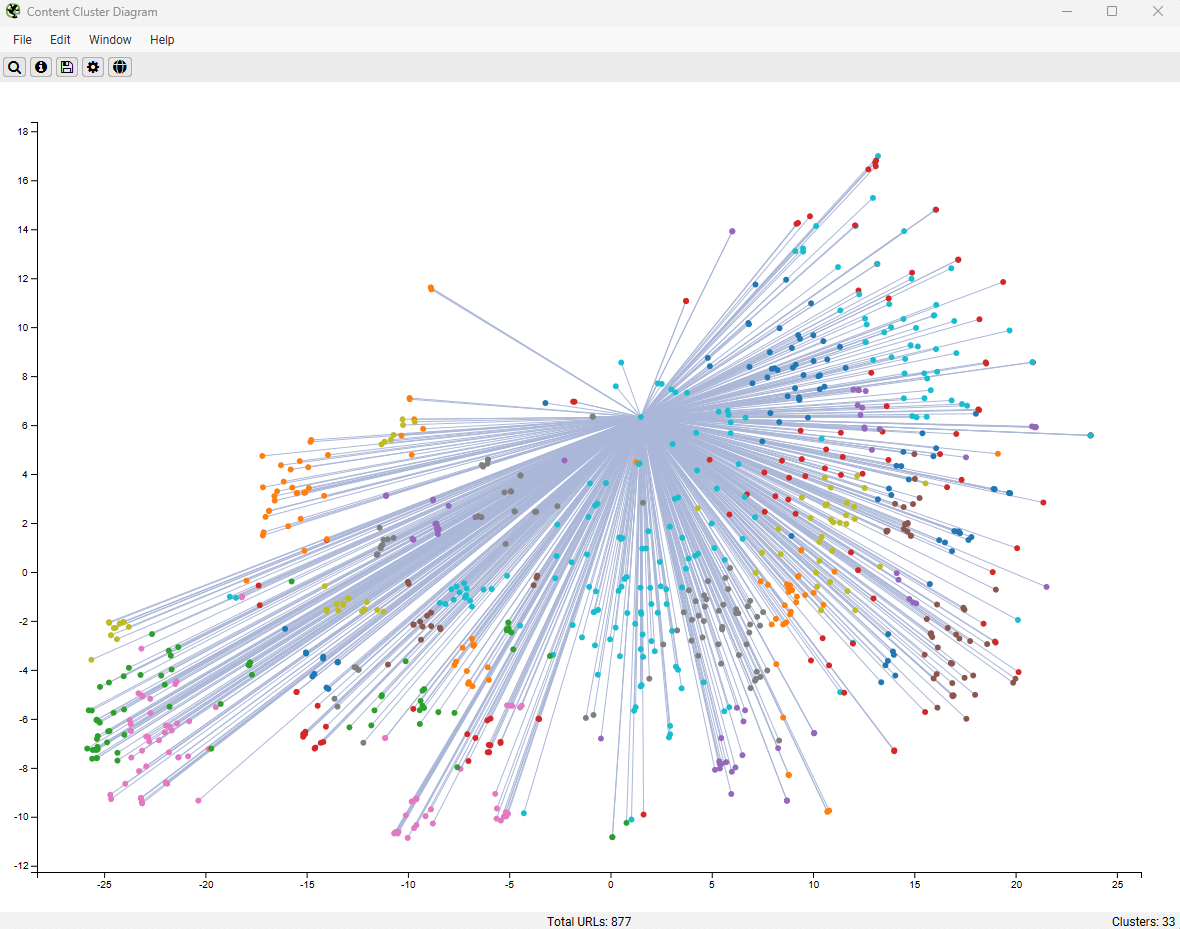
Xem Inlinks trong biểu đồ cụm nội dung ngữ nghĩa của Screaming Frog
Ngoài việc xem tất cả các liên kết nội bộ đến một trang, bạn còn có thể chọn ‘Show Inlinks Within Cluster’ (Hiển thị liên kết đến trong cụm) để xem liệu một trang có đang nhận được liên kết từ các trang có sự tương đồng về ngữ nghĩa hay không. Điều này cực kỳ quan trọng trong Semantic SEO, giúp bạn đánh giá mức độ gắn kết nội dung trong các chủ đề (topic clusters) và đảm bảo các trang liên quan được hỗ trợ lẫn nhau.
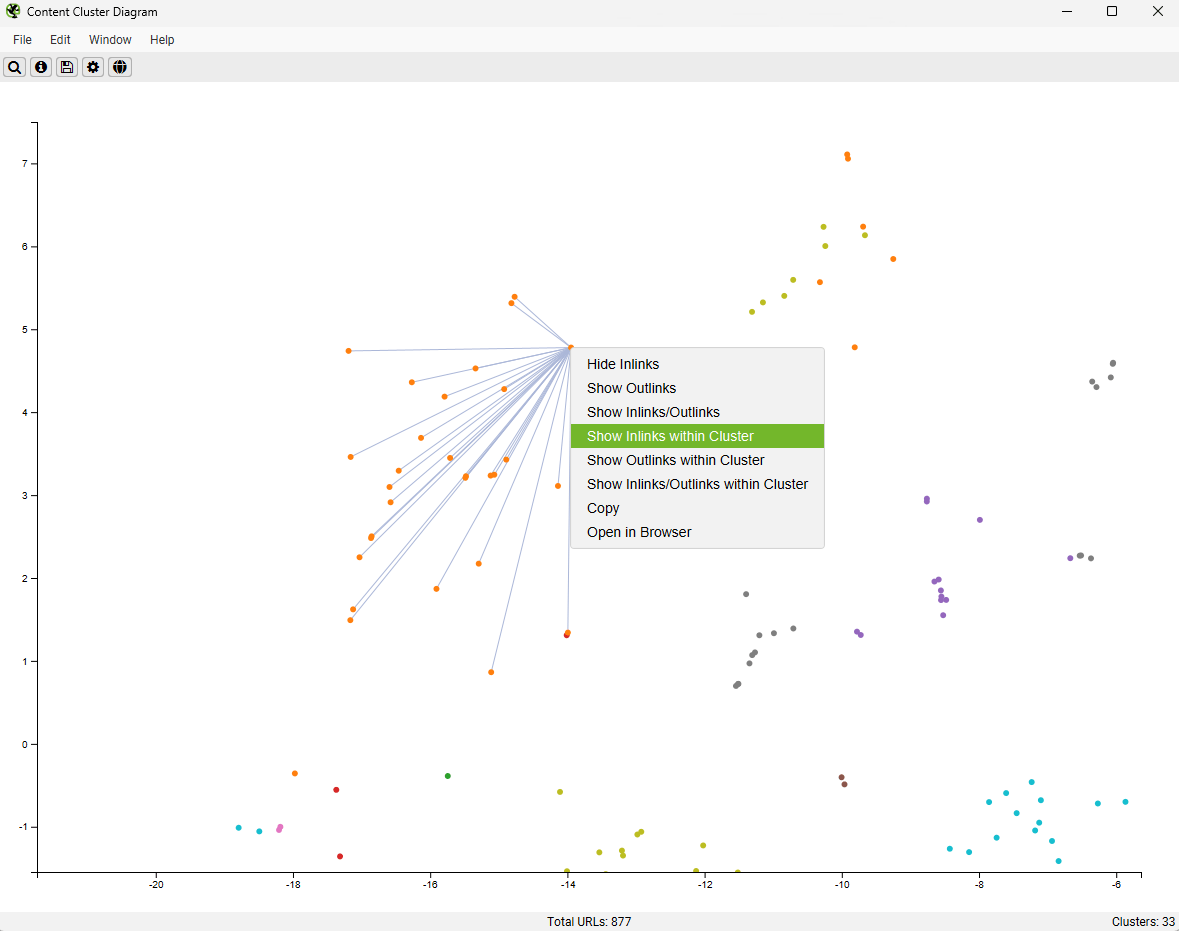
Phân tích Inlinks giữa các trang có cùng chủ đề ngữ nghĩa
Đây là một cách hữu ích để trực quan hóa và nhanh chóng xác định các cơ hội liên kết nội bộ hoặc các lỗ hổng trong chiến lược liên kết nội bộ dựa trên ngữ nghĩa. Việc tối ưu hóa các liên kết này không chỉ giúp cải thiện khả năng thu thập dữ liệu và lập chỉ mục của công cụ tìm kiếm mà còn tăng cường trải nghiệm người dùng, củng cố sự uy tín và liên quan của trang web trong mắt Google.
Các cập nhật khác
Phiên bản Screaming Frog SEO Spider 23.0 không chỉ mang đến những tính năng lớn mà còn tích hợp hàng loạt các cải tiến nhỏ nhưng vô cùng hữu ích, cùng với việc sửa lỗi và tối ưu hóa hiệu suất. Những cập nhật này thể hiện cam kết của Screaming Frog trong việc không ngừng nâng cao trải nghiệm người dùng và khả năng phân tích Technical SEO, giúp các chuyên gia SEO có thêm công cụ để hoàn thiện công việc của mình một cách hiệu quả hơn.
Dưới đây là tổng hợp các cập nhật đáng chú ý khác trong phiên bản Screaming Frog SEO Spider 23.0:
- Giới hạn tổng số crawl trên mỗi Subdomain: Trong ‘Config > Spider > Limits’, bạn có thể giới hạn số lượng URL được crawl trên mỗi subdomain. Tính năng này đặc biệt hữu ích khi bạn muốn crawl một số lượng mẫu URL nhất định từ nhiều domain khác nhau trong chế độ list mode, giúp tiết kiệm thời gian và tài nguyên.
- Cải thiện số lượng Heading: Trước đây, số lần xuất hiện (‘Occurrences’) của thẻ h1 và h2 trong các tab tương ứng chỉ giới hạn là ‘2’. Mặc dù chỉ hai tiêu đề h1 và h2 đầu tiên tiếp tục được trích xuất, nhưng giờ đây, số lần xuất hiện sẽ hiển thị tổng số lượng của mỗi thẻ h1/h2 trên một trang, mang lại cái nhìn chính xác hơn về cấu trúc tiêu đề.
- Nút di chuyển lên & xuống cho Custom Search, Extraction & JS: Thứ tự hiển thị (từ trên xuống dưới) ảnh hưởng đến cách chúng được hiển thị trong các cột của các tab (từ trái sang phải). Giờ đây, bạn có thể điều chỉnh thứ tự này mà không cần phải xóa và thêm lại, tăng cường hiệu quả làm việc khi hướng dẫn sử dụng Screaming Frog 23.0.
- Mã hóa phần trăm URL có thể cấu hình: Mặc dù việc mã hóa phần trăm URL thường là chữ hoa, nhưng một số ít máy chủ sẽ chỉ chuyển hướng sang chữ thường và gây ra lỗi. Do đó, tính năng này hiện có thể cấu hình trong ‘Config > URL Rewriting’, giúp bạn tránh được các lỗi PageSpeed trong Screaming Frog do vấn đề mã hóa.
- Hỗ trợ chính tả & ngữ pháp tiếng Ireland: Một bổ sung nhỏ nhưng thú vị cho những người dùng cần hỗ trợ ngôn ngữ này.
- Cập nhật mô hình AI cho System Prompts & JS Snippets: Các mô hình AI đã được cập nhật, bao gồm OpenAI lên ‘gpt-5-mini’, Gemini lên ‘gemini-2.5-flash’ và Anthropic lên ‘claude-sonnet-4-5’. Luôn khuyến nghị bạn nên xem xét các mô hình này và chi phí trước khi sử dụng.
- Các Exports & Reports mới: Có một xuất ‘All Error Inlinks’ mới trong ‘Bulk Export > Response Codes > Internal/External’, kết hợp các lỗi không phản hồi, 4XX và 5XX. Ngoài ra, còn có báo cáo ‘Redirects to Error’ mới trong ‘Reports > Redirects’, bao gồm bất kỳ chuyển hướng nào kết thúc bị chặn, không phản hồi, lỗi 4XX hoặc 5XX. Những báo cáo này rất quan trọng để Khắc phục lỗi PageSpeed trong báo cáo và các vấn đề kỹ thuật khác.
- Bộ lọc Redirection (HTTP Refresh): Mặc dù các chuyển hướng này đã được báo cáo và theo dõi, một bộ lọc mới đã được giới thiệu để báo cáo chúng tốt hơn, mang lại độ chính xác cao hơn trong việc phân tích các chuỗi chuyển hướng.
Đó là tất cả những gì có trong phiên bản Screaming Frog SEO Spider 23.0. Chúng tôi xin chân thành cảm ơn tất cả mọi người đã không ngừng ủng hộ, gửi yêu cầu tính năng và phản hồi. Vui lòng cho chúng tôi biết nếu bạn gặp bất kỳ vấn đề nào với bản cập nhật mới nhất này qua bộ phận hỗ trợ của chúng tôi.
Cập nhật nhỏ – phiên bản 23.1 phát hành ngày 18 tháng 11 năm 2025
Vào ngày 18 tháng 11 năm 2025, Screaming Frog đã phát hành một bản cập nhật nhỏ (phiên bản 23.1) cho Screaming Frog SEO Spider 23.0, chủ yếu tập trung vào việc sửa các lỗi phát sinh và thực hiện những cải tiến nhỏ để nâng cao trải nghiệm người dùng và ổn định phần mềm. Bản cập nhật này đảm bảo công cụ tiếp tục hoạt động mượt mà và hiệu quả hơn cho các chuyên gia Technical SEO.
Bản cập nhật 23.1 mang đến một loạt các điều chỉnh và sửa lỗi quan trọng, đảm bảo công cụ hoạt động ổn định và chính xác hơn:
- Thêm preset Shopify web bot auth header: Tên các header xác thực bot web của Shopify đã được bổ sung vào các cài đặt trước trong cấu hình HTTP Header, giúp việc thu thập dữ liệu từ các cửa hàng Shopify trở nên dễ dàng và hiệu quả hơn.
- Thêm cột ‘Indexability’ vào tab ‘Directives’: Một cột mới đã được thêm vào tab ‘Directives’, cung cấp cái nhìn trực tiếp và nhanh chóng về khả năng lập chỉ mục của các URL, hỗ trợ quá trình phân tích kỹ thuật SEO.
- Đánh dấu tính năng ‘Practice Problems’ rich result là deprecated: Tính năng rich result ‘Practice Problems’ của Google đã được đánh dấu là không còn được hỗ trợ.
- Bỏ cảnh báo deprecation cho ‘Book Actions’ rich result: Cảnh báo về việc không còn hỗ trợ tính năng rich result ‘Book Actions’ đã được loại bỏ.
- Cập nhật model tạo ảnh mặc định của Gemini: Mô hình tạo ảnh mặc định của Gemini đã được cập nhật, mang lại hiệu suất tốt hơn và chất lượng hình ảnh được cải thiện.
- Nâng cấp lên Java 21.0.9: Việc cập nhật lên phiên bản Java mới nhất giúp tăng cường hiệu suất, bảo mật và độ ổn định tổng thể của ứng dụng.
- Sửa lỗi không hiển thị ảnh srcset trong tab ‘Image Details’ khi tùy chọn trích xuất không được bật: Khắc phục vấn đề khiến ảnh có thuộc tính srcset không hiển thị đúng trong tab ‘Image Details’ nếu tùy chọn trích xuất không được kích hoạt.
- Sửa lỗi ‘Reset Columns for All Tables’ không hoạt động trong một số trường hợp: Đảm bảo chức năng đặt lại các cột cho tất cả các bảng hoạt động một cách nhất quán và đáng tin cậy.
- Sửa lỗi treo Multi-Export khi cấu hình segments: Khắc phục sự cố gây đóng băng ứng dụng khi người dùng cấu hình các phân đoạn và thực hiện xuất dữ liệu lớn.
- Sửa lỗi config cũ mặc định percent encoding về ‘none’ thay vì uppercase: Đảm bảo rằng các cấu hình cũ liên quan đến mã hóa phần trăm URL được xử lý chính xác, tránh các vấn đề về chuyển hướng hoặc thu thập dữ liệu URL không chính xác. Đây là một sửa lỗi quan trọng giúp tránh các lỗi PageSpeed trong Screaming Frog tiềm ẩn.
- Sửa lỗi chuột phải Inlinks/Outlinks không hoạt động trong một số visualisations: Khắc phục sự cố gây ra việc các tùy chọn hiển thị liên kết đến (Inlinks) và liên kết đi (Outlinks) không hoạt động trong một số biểu đồ trực quan hóa.
- Sửa lỗi trục content cluster diagram trong chế độ tối (dark mode): Cải thiện khả năng hiển thị và trải nghiệm người dùng khi sử dụng biểu đồ cụm nội dung trong chế độ tối.
- Sửa lỗi kiểm tra chính tả trên từ không đầy đủ: Nâng cao độ chính xác của tính năng kiểm tra chính tả, giúp phát hiện lỗi hiệu quả hơn ngay cả với các từ không hoàn chỉnh.
- Sửa lỗi tài khoản GA/GSC từ một instance khác ảnh hưởng lẫn nhau: Khắc phục sự cố khi dữ liệu từ các tài khoản Google Analytics và Google Search Console khác nhau bị ảnh hưởng lẫn nhau, đảm bảo tính độc lập và chính xác của dữ liệu.
- Sửa lỗi URL ‘Blocked by Robots.txt’ cũng xuất hiện trong bộ lọc ‘No Response’: Khắc phục vấn đề phân loại URL bị chặn bởi robots.txt, đảm bảo rằng chúng không bị nhầm lẫn với các URL không phản hồi, cải thiện độ chính xác của báo cáo.
- Sửa các lỗi crash duy nhất khác: Bao gồm nhiều sửa lỗi nhỏ khác nhằm nâng cao sự ổn định tổng thể của phần mềm.
Những cải tiến này cho thấy sự quan tâm đến từng chi tiết trong việc tối ưu hóa hiệu suất và tính năng của Screaming Frog SEO Spider 23.0, giúp người dùng có thể làm việc hiệu quả hơn khi hướng dẫn sử dụng Screaming Frog 23.0 và thực hiện các tác vụ SEO phức tạp.
Nguồn : Screaming Frog
Câu hỏi thường gặp về Screaming Frog SEO Spider 23.0:
Thay đổi lớn nhất trong tích hợp Lighthouse là gì?: Screaming Frog đã cập nhật theo Insight Audits của Chrome, hợp nhất nhiều vấn đề riêng lẻ thành các audit tổng quát như Improve Image Delivery để đồng bộ hóa dữ liệu.
Ai có thể sử dụng tích hợp Ahrefs API v3 mới?: Người dùng của bất kỳ gói trả phí nào (paid plan) đều có thể truy cập dữ liệu từ API v3, không còn giới hạn chỉ dành cho gói Enterprise như trước.
Tính năng Crawl Retention hoạt động như thế nào?: Tính năng này cho phép tự động xóa các bản crawl cũ sau một khoảng thời gian nhất định khi sử dụng chế độ lưu trữ database, giúp tiết kiệm dung lượng ổ cứng.
Semantic Similarity Embedding Rules dùng để làm gì?: Nó cho phép định nghĩa các quy tắc URL (ví dụ: loại trừ trang staging) khi thực hiện phân tích tương đồng ngữ nghĩa để map redirect chính xác hơn.
Làm sao để xem tất cả inlinks trong biểu đồ trực quan hóa?: Trong phiên bản 23.0, bạn có thể nhấp chuột phải vào một node trong biểu đồ site visualization và chọn Show Inlinks để xem toàn bộ liên kết trỏ đến.


